词法分析器与正则表达式窥探
正则表达式介绍
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
正则表达式常见规则
构造正则表达式的方法:用多种元字符与运算符将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为”元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
普通字符
| 字符 | 描述 | 实例 |
|---|---|---|
[ABC] |
匹配ABC串内的所有字符 |
用[ogl]匹配google可以匹配googl |
[^ABC] |
匹配除了ABC串内的所有字符 |
用[^ogl]匹配google可以匹配e |
[A-Z] |
[A-Z] 表示一个区间,匹配该区间内的所有符号 |
[0-9]匹配0到9的数字 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r] |
用[ogl]匹配google可以匹配google不包括换行符 |
[\s\S] |
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行 |
用其匹配google可以匹配google包括换行符 |
[\w] |
匹配数字,字母,下划线。等价于[A-Za-z0-9] | 例如可以匹配类似Ax0 |
非打印字符
| 字符 | 描述 |
|---|---|
\cx |
匹配由x指明的字符,如\cM匹配Control-M或回车符 |
\f |
匹配一个换页符 |
\n |
匹配一个换行符 |
\r |
匹配一个回车符 |
\s |
匹配任何空白字符,包括空格,制表符,换页符等等 |
\S |
匹配任何非空白字符 |
\t |
匹配一个制表符 |
\v |
匹配一个垂直制表符 |
特殊字符
| 字符 | 描述 |
|---|---|
$ |
匹配输入字符串的结尾位置 |
() |
标记一个子表达式的开始和结束位置 |
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
. |
匹配除换行符 \n 之外的任何单字符 |
[ |
标记一个中括号表达式的开始 |
? |
匹配前面的子表达式零次或一次 |
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符 |
^ |
匹配输入字符串的开始位置,当在方括号表达式中使用时,表示不接受方括号表达式中的字符集合 |
{ |
标记限定符表达式的始 |
| ` | ` |
限定符
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
? |
匹配前面的子表达式零次或一次 |
{n} |
n 是一个非负整数。匹配确定的 n 次 |
{n,} |
n 是一个非负整数。至少匹配n 次 |
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次 |
从状态机的视角来审视正则表达式
以邮箱表达式的匹配规则对应生成的状态图为例
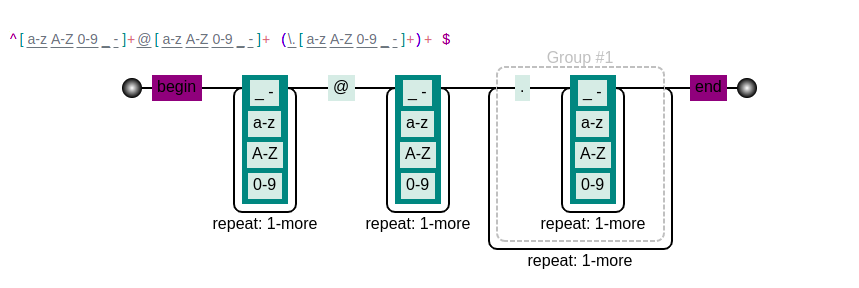
从状态图来看,首先我们会进入第一个匹配模块,该模块可以匹配数字,字母和下划线一次或者多次,其实这里写代码的话就会对应着一个while循环。紧接着是@的匹配,然后类似第一个的循环。最后是两个循环的匹配,每个循环都匹配一个.xxx的串。这也是符合邮箱的格式的。通过这个图形我们可以很直观的看到一个具体的识别过程,另外其实也可以说明我们的每一个正则表达式都可以转化为一个状态图。那么我们的token识别本质上就是一个token对应一个状态机,而一个状态机对应一个正则表达式。所以用正则表达式来匹配token是可行的,而且其的优势在于它在直观上看减少了代码量,因为其不用显示的书写各种循环代码。虽然其本质工作可能依然没有改变,但是对上层人员编写可读性更高的代码提供了可能。
C语言对应的正则表达式函数结构概览
C语言也对正则表达式的识别进行了封装,使用时,我们需要引入头文件<regex.h>,一般用以下三个步骤进行使用:
- 使用
regcomp()将字符串编译为正则表达式 - 用上一步得到的正则表达式,调用
regexec()来对输入进行匹配 - 使用完毕调用
regfree()释放正则表达式 - 如果出错,调用
regerror()输出
下面是具体的介绍:
regcomp()函数
1 | int regcomp(regex_t *preg, const char *regex, int cflags); |
regex_t是一个结构体数据类型,用来存放编译后的正则表达式。regex我们编写的表达式指针。cflags有如下4个值或者是它们或运算(|)后的值:REG_EXTENDED以功能更加强大的扩展正则表达式的方式进行匹配。REG_ICASE匹配字母时忽略大小写。REG_NOSUB不存储匹配后的结果。REG_NEWLINE识别换行符,以便$从行尾开始匹配,^从行的开头开始匹配。
regmatch_t 结构
1 | typedef struct { |
rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。有了这一结构,我们就可以将识别到的关键字,标识符和整数存储到指定位置。
regerror()函数
1 | size_t regerror(int errcode, const regex_t *preg, char *errbuf, |
当执行 regcomp 或者regexec 产生错误,就可以调用这个函数而返回一个包含错误信息的字符串。errbuf在这里作为传出参数,我们需要声明一块用于存储错误信息的地址,然后传入,如果出错,可从该地址查看具体的错误信息。
regexec()函数
1 | int regexec(const regex_t *preg, const char *string, size_t nmatch, |
当我们编译好正则表达式后,就可以调用regexec 来匹配我们的目标文本串,如果在编译正则表达式的时候没有指定cflags的参数为REG_NEWLINE,则默认情况下是忽略换行符的,也就是把整个文本串当作一个字符串处理。执行成功返回0
preg: 用regcomp函数编译好的正则表达式。string:目标文本串。nmatch:regmatch_t结构体数组的长度。pmatch[]:regmatch_t类型的结构体数组,存放匹配文本串的位置信息。eflags有二个取值
REG_NOTBOL:指定之后,就不会匹配开始的^字符,
REG_NOTEOL:指定之后,就不会匹配结束的$字符,
regfree()函数
1 | void regfree(regex_t *preg); |
清空preg指向的regex_t结构体的内容。
词法分析
词法分析程序设计
在词法分析这一部分,我们主要采用正则表达式来识别我们WHI语言中的具体词素,而关于正则表达式的具体设计,我们在上面对其进行了简要的介绍,并引入了C语言中与之对应的库函数。我的大致思路是,对每一个要识别的token都编写一个与之对应的正则表达式,然后用相应的库函数将其构造为C语言中标准的正则表达式结构。之后读入我们的程序源文件,识别出每一个token,对于标识符,关键字,整数则将其存储到制定的位置。
具体的规则编写在上述文章已经介绍过,再次不做赘述,每个正则表达式的对应规则如下
1 | struct rule { |
这里我们以变量名的识别为例,进行介绍。首先对于正则表达式的规则[a-z]+[0-9a-z]*,由于我们的变量只由小写字母和数字组成,且必须以小写字母开头,因此我们首先用[a-z]+识别一个或多个小写字母,然后用[0-9a-z]*识别数字和字母的组合,其中后面的部分可以重复0次或多次,也即我们的正则表达式需要匹配纯字母或单字母的情况。
正则表达式初始化构造
其实有了上面的铺垫后,这一部分就显得比较简单了,具体就是调用regcomp将我们上面指定的字符串规则构造为可以识别的正则表达式。具体如下:
1 | void init_regex() { |
匹配识别
至于匹配识别这一部分就需要考虑的稍微多一些,具体我们要考虑的点有如下几个
- 区分需要存储的和不需要存储的
- 对于关键字和标识符以及整数需要将识别到的子串进行提取存储
- 区分开关键字和标识符
- 将标识符加到全局变量表中
- 加入全局变量表的标识符不能重复且必须是
var和;之间识别到的标识符。
以这个思路,我们分别对应的解决措施
- 用
case语句分开不同的情况 - 利用
regmatch_t结构体的信息进行子串的提取 - 构造关键字表,书写
is_keyword()函数,如果是关键字返回其类型,不是返回-1 - 构造全局符号表,利用
addglob()函数将标识符加入其中,利用searchslot()可以返回其具体位置,也即建立标识符和全局符号表之间的映射关系。 - 加入静态全局变量
add_gsyt_flag,初始值为0,识别到var将其设置为1,识别到;将其设置为0。另在调用addglob()函数时,判断add_gsyt_flag,为1则调用加入,为0不执行。
具体的部分代码如下
1 | switch (rules[i].token_type) { |
测试
测试文件
1 | var x0, y0, x, y, g, m, temp; |
识别结果
1 | token type=> [271] token value => [var] position =>(1,0) |