递归下降语法分析
语法分析设计
设计概要
关于错误处理部分的设计
对于错误处理,我们主要将所有的错误类型定义在一个结构体中
1 | struct grammer_error{ |
之所以将其分离开来,而不是直接在有错误的地方用printf打印的主要原因在于,尽量减少模块之间的耦合性。而且这样设计的好处还在于,我们可以在结构体中加入更多的特性,比如后期可能为每一个错误处理增加一个出错处理函数(如注释部分所示),当我们识别到具体的错误时就对其进行一定的处理达到识别多个错误的目的,而不是简单的识别一个错误然后直接退出,这样可以减少用户因多个错误导致的多次编译。
关于非终结符解析函数部分的设计
而在函数解析部分,其实最重要的一个点就是递归调用的思想以及在合适的时机获取token,因此就需要明确token的获取时机,故我们对获取时机做出以下规定:
- 对于每一个子过程的调用都直接带着一个已经读入的
token进行分析 - 当子过程调用结束时,要获取下一个
token,用于下一个过程的分析识别
辅助函数match()的设计
为了匹配识别我们的具体的token,在helper.c文件中加入了match(Token_t hold, int expected)函数,它主要的工作在于将hold和expected进行比较,然后返回判断结果,我并没有直接在文件中用if语句进行判断,主要理由在于分开有利于出错函数的插入和后续功能的增加,例如若我们想要在匹配到某一个token的时候,加入一些额外的输出信息,或者进行一些处理,那么就可以直接加入对应的模块,从而进一步与解析函数进行解耦合。另判断两个token是否相等这一功能使用比较频繁,因此封装为函数也更为合理。
识别多个错误
在考虑一遍扫描中识别多个错误的情况时,我们需要明确以下几点:
- 不存在缺少的
token,只是对应位置类型不匹配,如=做赋值运算符- 使用未定义的变量
- 存在缺少的
token,如- 分号,逗号的缺失
- 括号不匹配
- 存在多余的
token- 分号,逗号的多余
- 括号不匹配
对应的解决方案是
- 对于第一种情况,我们不用额外考虑措施,因为其不会打乱程序的正常执行,只是会引发类型不匹配的错误
- 对于第二种情况,我们需要插入缺失的
token,从而使执行流恢复正常 - 对于第三种情况,我们需要删除多余的
token,其实也即跳过多余的token
然而,存在的问题是我们如何确定,此次的出错是由于上述的那一种情况造成的,为此我们需要定义以下的几个规则以判别此次的出错种类。故作出下列的规定:
| 语句类型 | 多余定义 | 缺失定义 | 匹配错误 |
|---|---|---|---|
| 类型声明 | 连续识别到两个,号 |
连续识别到两个identifier |
,号写成其它可通过词法检查的符号 |
| 赋值语句 | :=前或后连续识别到两个identifier |
无:=或者:=后无identifier |
:=号写成其它可通过词法检查的符号 |
| 表达式语句 | 连续识别到两个运算符或者多余括号 | 连续识别到两个identifier或者括号不匹配 |
运算符写成其他可通过词法检查的符号 |
if语句 |
同表达式 | 缺失关键字或;号 |
合并赋值和表达式的情况 |
while语句 |
同表达式 | 缺失关键字或;号 |
合并赋值和表达式的情况 |
read语句 |
多个括号或者括号内多个变量 | 括号内无变量,无左括号或右括号 | identifier未定义 |
write语句 |
同表达式 | 同表达式或者括号不匹配 | 同表达式 |
示例
可一次性识别错误类型示例如下
|错误类型|示例|
|-|-|
|声明语句连续的,号|a,,b|
|缺少;号|var x,y,z|
|while语句缺少关键字|while a < b x := y od|
|if语句缺少关键字|if a < b then x :=y skip|
|read语句括号不匹配|read((x)), read(x, read x)|
|read语句含多个变量|read(x y)|
|write语句括号不匹配|write(x, write a+b) |
|表达式连续两个运算符|a <= b, a == b, a ** b|
|表达式缺少运算符|a b, 10 7|
|表达式缺少右括号|(a = b|
|表达式存在多余的右括号|(a = b))|
|赋值符号错误写成其他符号|a = b|
|变量未声明,假设b未声明|a := b|
代码示例
1 | /** |
我们以write(E)的多错误处理为例来介绍我们的基本思想的实现。首先对于没有左括号的情况,我们需要在进入parse_write_statement() 函数就提前判断下一个token,如果不是(,那么证明我们缺失左括号,这时我们调用handle_missing()函数来在输入流中插入一个(括号,并调用get_token()获取这个(括号,另外我们还需要将超前读入的identifier或者其他标识符放回到tokens数组中,即调用putback()函数,而对于存在额外的)括号这一点,我们就需要考虑左右括号的数量关系,为此我们设立了两个变量right_parentheses_cnt, left_parentheses_cnt,他们只会在match函数中匹配到左右括号时自增,那么如果我们查看下一个token,发现它为右括号并且其加一的数量不等于左括号的数量,证明我们的右括号存在多余,此时我们就需要跳过多余的右括号,就调用handle_extra()函数,其在内部多调用一次get_token()。反之如果左右括号数量相等,我们不做处理。
识别条件的判断
当读入一个token,需要判断要调用那一个子过程来进行识别,本质上就是对每一个非终结符求FIRST集,然后根据不同的符号,匹配进入不同的识别过程,下面是WHI语言的文法的非终结符的FIRST集
| 非终结符 | FIRST集 |
|---|---|
| P | {var, skip, read, write, if, while, id(FIRST(C))} |
| X | {var} |
| L | {skip, read, write, if, while, id(FIRST(C))} |
| S | {skip, read, write, if, while, id(FIRST(C))} |
| E | {num(FIRST(G)), id(FIRST(C)), (, ~} |
| TS | {+, -} |
| T | {num(FIRST(G)), id(FIRST(C)), (, ~} |
| FS | {*, /} |
| F | {num(FIRST(G)), id(FIRST(C)), (, ~} |
| D1 | {=, <} |
| D | {num(FIRST(G)), id(FIRST(C)), (, ~} |
| N | {num(FIRST(G))} |
| V | {id(FIRST(C))} |
| G | {num(FIRST(G))} |
| C | {id(FIRST(C))} |
其中,num(FIRST(G)), id(FIRST(C))分别对应着TK_NUM,TK_IDENTIFIER,也即当终结符为G,C时,我们调用函数match(Token_t hold, Token_t expected)来检查当前token是否相匹配。
识别过程
首先根据文法的BNF范式

在具体解析的时候,我们需要根据文法的每一个非终结符。编写对应的解析函数。以变量声明为例
1 | /** |
根据变量声明的文法X ::= var V {',' V},在程序一开始我们会识别到一个var关键字,然后经过层级间的调用,进入到变量声明的解析。首先需要识别一个标识符,然后通过get_token()函数获取下一个token,判断是不是,,若是一个,号,那么证明我们需要继续对变量声明的解析,进入while循环,首先匹配识别一个,号,然后获取下一个token,匹配其是否为一个标识符,之后重复这个过程。当然这里其实多判断了一步,即识别到一个,号然后进入循环,又匹配其是否为,号,显得似乎有些重复,但是主要目的在于统一识别的形式,使整个过程与语法的描述更加的贴合,也更利于理解。而对于识别结束的判断,我们主要判断当前拥有的hold_token是否为;,若是那么证明我们对变量的解析结束,直接返回,匹配一下个过程,但需要注意的一点是因为我们当前的token是;,所以需要将提前读入的;号放入原tokens数组,即调用putback()函数。
语法解析的错误处理
当我们发现文法中出现语法错误,也即在合适的位置出现的不是我们所期待的token我们就需要报出错误,提示用户进行改正。而在错误处理这一部分,我主要定义了如下的错误类型,然后在每一个非终结符对应的解析函数的合适的位置插入错误处理函数handle_error()。我们需要将出错的行列信息和出错码传递给出错处理函数,其在内部调用Log()函数,进行一个简单的提示信息打印,为了更加的醒目,我为出错处理提示信息加上了颜色。
| 错误类型种别 | 描述 |
|---|---|
ERROR_x00 |
missing ; |
ERROR_x01 |
declaration syntax error |
ERROR_x02 |
division by zero |
ERROR_x03 |
expression syntax error |
ERROR_x04 |
variable undeclaration |
ERROR_x05 |
while statement must have od |
ERROR_x06 |
while statement must have do |
ERROR_x07 |
if statement must have fi |
ERROR_x08 |
expect ( |
ERROR_x09 |
missing ) |
ERROR_x10 |
declaration missing ',' |
ERROR_x11 |
unknown mistake |
ERROR_x12 |
if statement must have else |
ERROR_x13 |
if statement must have then |
ERROR_x14 |
expect ':=' |
ERROR_x15 |
expect 'read' keyword |
ERROR_x16 |
expect 'write' keyword |
ERROR_x17 |
expect '~' |
ERROR_x18 |
expect 'while' keyword |
ERROR_x19 |
expect 'if' keyword |
ERROR_x20 |
expect 'skip' keyword |
ERROR_x21 |
expect a arithmetic operators such as '+','-','*','/' |
ERROR_x22 |
expect a relational operator such as '=' and '<' |
ERROR_x23 |
expect a decimial int number |
ERROR_x24 |
program aborted unexpectedly, exited with -1 |
ERROR_x25 |
extra ';' |
ERROR_x26 |
extra ',' |
ERROR_x27 |
extra ( |
ERROR_x28 |
extra ) |
ERROR_x29 |
there must be a variable inside the parentheses |
ERROR_x30 |
only one variable within the parentheses of a read expression |
ERROR_x31 |
operator is required between two identifiers |
ERROR_x32 |
operator is required between two num |
ERROR_x33 |
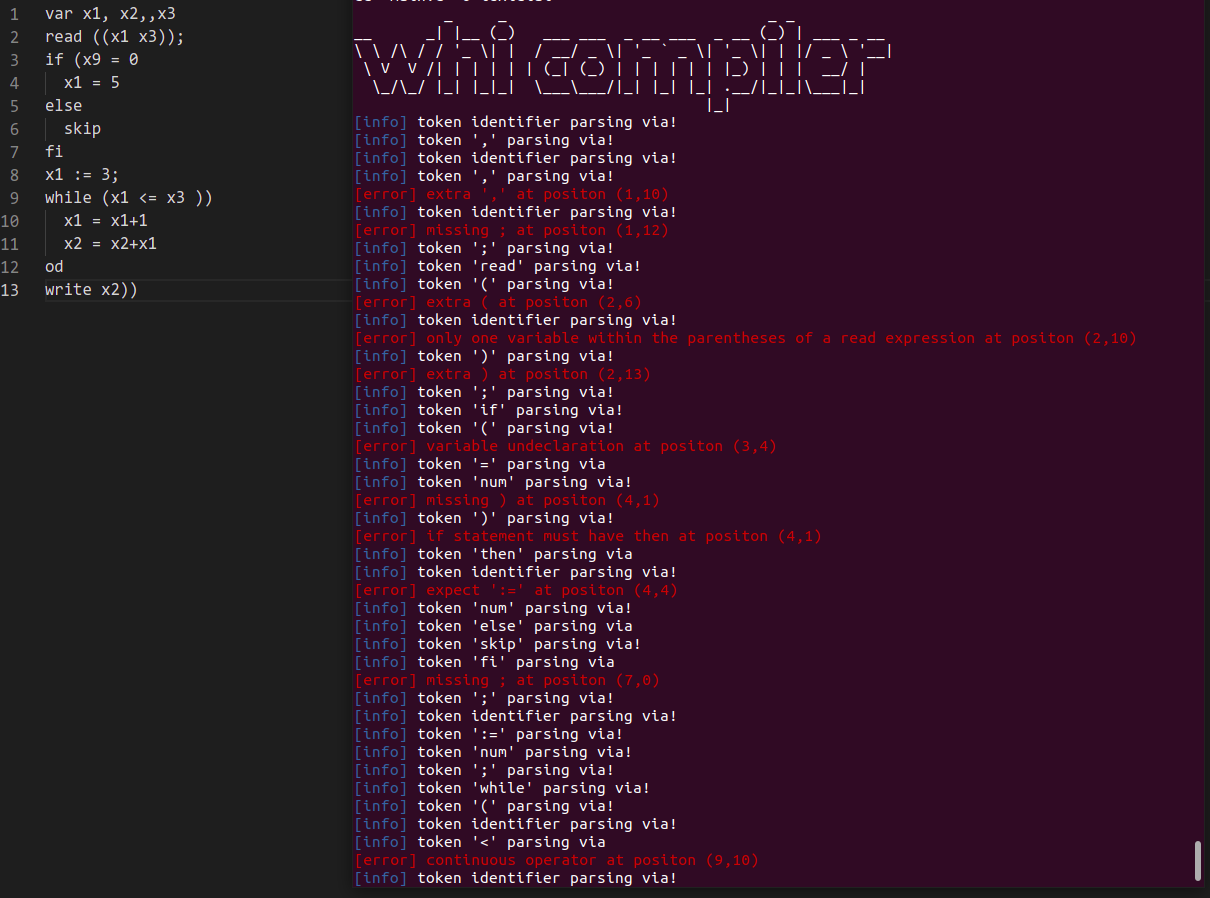
continuous operator |
此处的错误类型定义可能并未完全使用到,诸如ERROR_x02,是语义层面的错误,语法层面无法暂时未对此情况作出处理。最终的效果如下图所示: